
What is Memory Consolidation for AI Agents?
How AI systems learn to remember what matters

TL;DR
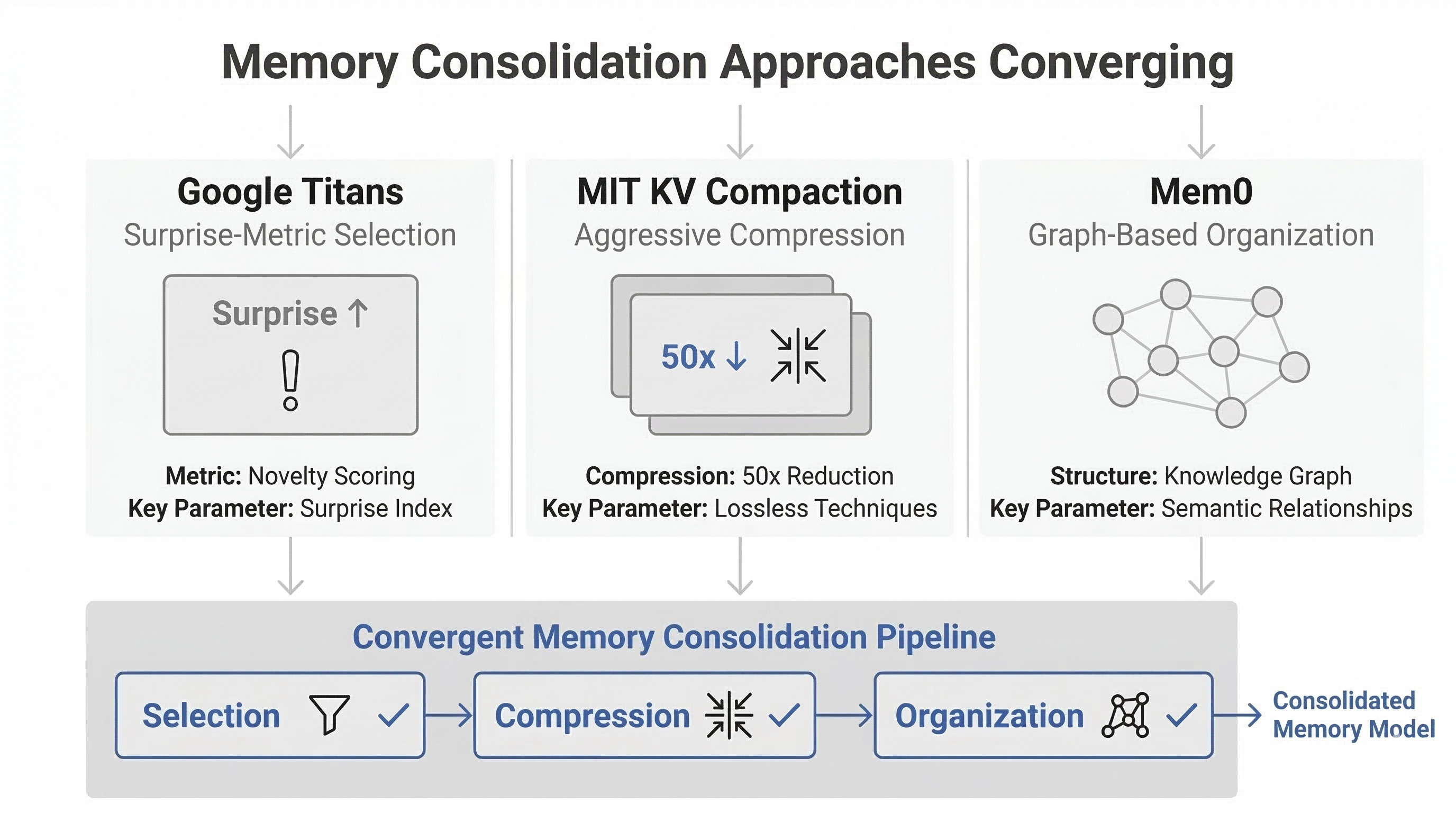
AI agents compress and prioritize memories just like human brains do during sleep, but on inference timescales
Google’s Titans uses a “surprise” metric to decide what to store long-term; MIT’s Fast KV Compaction achieves 50x compression without losing accuracy
The core challenge isn’t storing more, it’s deciding what’s worth keeping, how to compress it, and guaranteeing important memories stay retrievable when needed
The Problem With Infinite Memory
Most language models today have a fundamental limitation: they can only “remember” what fits in their context window. A 2M-token window sounds impressive until you ask a system to handle a month of conversations, customer interactions, or research synthesis. Everything before that window vanishes.
But here’s the counterintuitive part: infinite memory would actually be worse. Humans don’t remember every conversation, meal, or thought. We consolidate. We strengthen important memories while letting trivial ones fade. We reorganize experiences into narrative patterns and abstract knowledge.
AI systems face the same computational pressure. When an agent processes millions of tokens, storing every detail is inefficient. The real question isn’t how to remember everything. It’s how to remember what matters in a way that’s both compact and reliable.
That’s memory consolidation.
What Actually Happens During Memory Consolidation
Memory consolidation isn’t a new concept. Neuroscience has studied it for decades. When humans sleep, the brain runs something like a compression algorithm: it replays recent experiences, strengthens connections between related concepts, and prunes details that don’t fit into larger patterns. A single conversation about your career might get compressed into a few key insights that integrate with your existing knowledge.
AI memory consolidation works on a similar principle, except it happens in real time or semi-real time, not overnight.
The process has three overlapping stages. First, selection: which memories are worth keeping? A conversation with a user where they mention an unusual preference matters more than small talk. A failed approach to a coding problem matters more than a successful one (it helps avoid repeating mistakes). Something unexpected, even surprising, often signals importance.
Second, compression: how do you shrink selected memories without losing critical details? This is where the technical depth emerges. You can’t just truncate. You need to preserve relationships, context, and the reasons why something matters.
Third, organization: how are compressed memories stored and linked so they’re retrievable? A simple list of facts is less useful than a graph where related ideas are explicitly connected. If a user mentioned they work in biotech and later asks about regulatory compliance, the system should connect those threads.
When all three stages work well, an agent can handle vastly longer interaction histories than its context window would allow.
Google’s Titans: Using Surprise to Decide What Matters
Google’s Titans architecture uses MIRAS (Multi-scale Interval Retrieval Attention-based Summarization) to handle sequences longer than 2 million tokens. The key insight is deceptively simple: use a “surprise” metric to decide what gets stored long-term.
In information theory, surprise is the difference between what you expected and what actually happened. If an AI system reads a sentence that perfectly matches its predictions, it’s low surprise. If something unexpected occurs, surprise spikes. That spike signals: this is information you should remember.
Titans takes this further. It maintains multiple scales of memory. Recent interactions live in high-resolution detail. Older interactions get progressively compressed using the surprise signal. What’s surprising at one timescale might be routine at another, so the system keeps this multi-scale view.
The result: 2M+ token sequences without the quadratic memory cost of standard attention. More importantly, the system automatically learns what’s worth detailed retention and what can be aggregated. No human engineer had to define “here’s what matters.” The architecture discovered it.
The assumption many people hold is that larger context windows solve the memory problem. Titans suggests that’s backwards. The constraint isn’t getting information in, it’s deciding what to keep once you’ve processed it.
MIT’s Fast KV Compaction: Losing Information Strategically
MIT’s Fast KV Compaction via Attention Matching tackles a different bottleneck. In transformer-based systems, key-value caches grow linearly with sequence length. For long conversations or repeated interactions, this becomes expensive.
The technique, described in the paper “Fast KV Compaction via Attention Matching”, compresses these caches 50x without accuracy loss. How? By identifying which keys and values actually matter to the attention mechanism’s decisions. Some tokens barely influence what the model outputs. Removing them changes nothing. Some are essential: their absence breaks downstream reasoning.
Fast KV Compaction uses attention weights themselves as the guide. It measures which keys and values contribute most to each query, then keeps the high-impact ones while dropping low-impact ones. The result is a smaller cache that still passes the same information forward.
This is where the misconception about “lossy” compression often appears. People worry that any compression means losing critical information. But intentional information loss can be smarter than keeping everything. If a token contributes 0.01% to your output and uses 1% of your memory, dropping it is a win.
The challenge this exposes is selectivity. How do you know which information is truly low-impact? It’s not obvious in open-ended reasoning. A fact might seem irrelevant until a rare query makes it essential. The MIT approach works well for specific patterns, but generalizing it to unpredictable agent behaviors requires more subtlety.
Mem0: Memory as a Structured System
Mem0 (arXiv:2504.19413) represents a more complete approach to memory consolidation for agents. Rather than optimizing at the architecture level, it treats memory as a first-class system: extracting memories from interactions, organizing them into a graph, updating them as new information arrives, and retrieving the right ones when needed.
The system works like this. After each interaction, it extracts factual claims, preferences, and insights from the conversation. These become nodes in a graph. Relationships between nodes are explicitly mapped. Over time, similar memories merge, contradictions resolve, and the graph becomes increasingly organized.
The accuracy improvement is striking: 26% better performance on memory-dependent tasks than naive approaches. But equally important is the latency gain: 91% lower latency. This matters because a memory system that takes forever to retrieve useful context doesn’t help real agents.
The graph structure deserves attention. Without it, retrieval is probabilistic. You search for relevant memories and hope the ranking algorithm surfaces the right ones. With explicit relationships, retrieval becomes more direct. If the user mentioned they work in regulatory affairs, that node connects to any relevant domain knowledge, past conversations about compliance, and personal preferences documented in that context.
Mem0 also addresses the update problem: what happens when new information contradicts or refines old memories? A naive system would duplicate entries. Mem0 consolidates. It integrates new information, marks what’s changed, and maintains consistency.
This moves memory from a passive storage problem to an active reasoning component. The system doesn’t just retrieve facts; it synthesizes, updates, and reasons about what it remembers.
The Three Core Technical Challenges
Beneath these approaches lie three challenges that separate production memory systems from toy implementations.
What to store. The surprise metric from Titans is elegant, but surprise is context-dependent. An agent handling medical information needs different criteria than one handling entertainment. And surprise alone misses important categories like: explicitly taught preferences, factual corrections, safety-relevant information. Finding the right combination of signals that works across diverse agent tasks remains open.
How to compress. Fast KV Compaction works brilliantly when you know exactly what you’re preserving (attention weights). But when you’re consolidating semantically, compression is harder. How do you shrink “the user mentioned they worked in biotech for fifteen years and just switched to finance” into something smaller without losing information density? Mem0’s graph approach helps by treating relationships explicitly, but the compression itself still requires careful design.
Guaranteeing retrievability. This is the most underrated problem. You can have perfect compression and perfect storage, but if retrieval fails, the memory system is useless. The system needs to answer: “Do I have any memories related to this query?” reliably and fast. This isn’t just a search problem. It’s a problem of ensuring your memory structure makes the right connections observable. A graph with poor edge definitions will have nodes that stay isolated even when they’re related.
These three challenges are why memory consolidation remains an active research area rather than a solved problem. Each approach we’ve discussed prioritizes different tradeoffs. Titans optimizes for scale. MIT’s work optimizes for efficiency. Mem0 optimizes for integration and consistency.
Memory Consolidation as a First-Class Capability
The importance of memory consolidation is often underestimated because it’s not flashy. It’s not a new activation function or a clever training trick. It’s infrastructure.
But infrastructure is how systems scale from toy problems to real ones. An agent that can genuinely learn from long histories and build on prior interactions is fundamentally different from one that starts fresh each session. It can develop deeper relationships with users. It can accumulate domain expertise. It can avoid repeating mistakes.
The convergence happening now, with Google, MIT, and open-source projects all attacking this problem from different angles, suggests the field is moving from “nice to have” to “essential.” As systems take on longer-lived roles, memory becomes load-bearing.
The technical challenges aren’t trivial, and they don’t have one-size-fits-all answers. But the frameworks are emerging. The question for teams building agents isn’t whether to invest in memory consolidation. It’s which approach fits their constraints.
References and Further Reading
Titans: An LLM Library for Long Context Infinities - Google’s MIRAS architecture for 2M+ token sequences using surprise-based memory selection
Fast KV Compaction: Reducing Memory and Computational Overhead in Language Models via Token Selection - MIT’s approach to 50x key-value cache compression
Mem0: A Personal Knowledge Base for Agentic Systems - Graph-based memory consolidation with selective indexing
The Neuroscience of Sleep and Memory Consolidation - Foundational neuroscience work on biological memory consolidation
Attention Is All You Need - Transformer architecture and context window mechanics
Everything About Long Context Fine-tuning - HuggingFace overview of long-context approaches in modern LLMs
Long Context Language Models: Architecture, Training, and Applications - Comprehensive survey of long-context techniques