
What Is Harness Engineering?
The Discipline That Just Replaced Model Choice as the Top Performance Lever

Five sentences to take with you
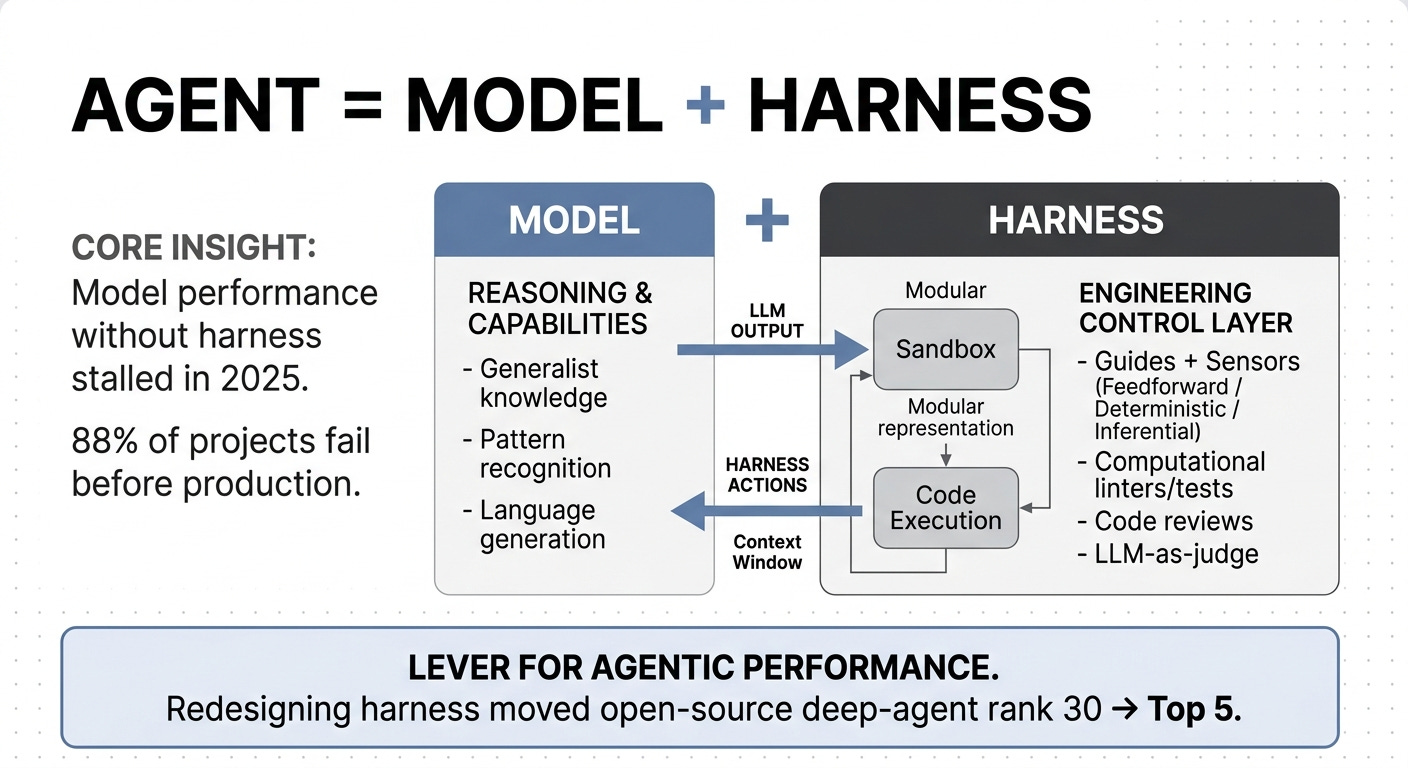
The 2026 equation that finally stuck: Agent = Model + Harness, where the harness is every piece of code, config, and runtime around the LLM.
LangChain moved its coding agent from rank 30 to top 5 on Terminal Bench 2.0 with no model swap, and Anthropic’s 2026 Agentic Coding Trends Report says harness setup alone can swing benchmarks by 5+ percentage points.
The five primitives most working harnesses install are filesystem, code execution, sandbox, memory, and context management.
Distinct from prompt engineering (what you say) and context engineering (what fills the window); it’s about designing the whole system around the model.
88% of agent projects never reach production, and that number has not improved as the models have improved.
A frontier-class language model dropped into a project, on its own, is not yet useful.
Give it a question and it answers reasonably. Hand it a codebase and ask it to fix a bug, and the median outcome is something between “good attempt” and “deletes the wrong file.” Wrap that same model in a stack of tool definitions, sandboxes, retry policies, progress files, and review agents, and you get something that ships pull requests. The model is the same. The result is not.
That gap, between “model in a chat window” and “agent that actually delivers work,” is the territory of the discipline now called harness engineering.
The equation that finally made the term stick
Earlier in 2026, Mitchell Hashimoto wrote down the cleanest framing the field had managed so far: Agent = Model + Harness. The model is what does the reasoning. The harness is everything else.
That definition sounds suspiciously broad. It is. The harness is system prompts, tool definitions, state files, sandboxes, retry logic, observability hooks, evaluators, permissions, memory stores, compaction strategies, planning artifacts, and the runtime that ties them together. Anything in an agent that isn’t the model is the harness.
The breadth is the point. For years the AI community talked about “prompt engineering” as if the only thing between a model’s raw output and a useful product was a few well-chosen words. Then we noticed context windows mattered as much as prompts, and called the new layer “context engineering.” Now we’re noticing that even great prompts and great context don’t get you to production. The thing that does is the entire scaffolding around the model. The community settled on calling that scaffolding a harness, and harness engineering is the discipline of designing it.
Birgitta Böckeler at Thoughtworks has the cleanest mental model I’ve seen for the user view of harness engineering: a harness is guides (feedforward controls that anticipate the agent’s behavior before it acts) plus sensors (feedback controls that observe after the agent acts and help it self-correct). Each can be computational (deterministic, run by a CPU: linters, tests, type checkers) or inferential (probabilistic, run by a model: code review agents, LLM-as-judge). A well-designed harness is the right mix of all four.
Why this isn’t just a rebrand of “agent frameworks”
There’s a fair objection here. People have been building “agent frameworks” since 2023. LangChain, LlamaIndex, AutoGPT, AutoGen, CrewAI. Isn’t harness engineering just the new name for the same thing?
It isn’t, for a specific reason. Agent frameworks gave you a way to write an agent. Harness engineering is concerned with everything you have to put around the agent to make it reliable, repeatable, and safe. A framework gives you the agent loop. A harness gives you the spec, the sandbox, the review, the sensors, the recovery file, and the eval suite. The framework is one component of the harness, not the whole thing.
You can build a great harness on top of any framework. You can also build a terrible harness on top of any framework. The framework choice matters less than people thought.
The five primitives almost every harness installs
LangChain’s anatomy-of-an-agent-harness post lays out what’s now the standard decomposition of what’s inside a working harness.
Filesystem. The agent needs a place to put files and read them back later. Code lives here. Progress notes live here. Checkpoints live here. Without persistent storage, the agent forgets everything between turns.
Code execution. The agent needs to be able to run code and observe what happens. This is the difference between a chatbot and an agent. A model that proposes a Python script is a chatbot. A model that proposes a script, runs it, sees the traceback, and tries again is an agent.
Sandbox. Code execution without isolation is a footgun. The sandbox is what stops the agent from rm -rfing your data folder or pushing to main while you’re not looking. It’s also what makes verification possible: you can run an agent’s proposed change against the real test suite without trusting the agent first.
Memory. Filesystem persists files; memory persists understanding. Memory is the bridge between sessions, the index of what the agent has tried, the structured map of the codebase, the record of what worked last time. Without memory, every session starts from scratch.
Context management. Context windows are finite. As a session grows, the harness has to decide what stays in the window and what gets summarized, archived, or dropped. Modern harnesses do this with compaction (summarize older context into a brief), retrieval (pull relevant context back when needed), and what LangChain calls autonomous compaction (let the agent decide when to compress, instead of waiting for the window to fill).
Almost every working harness in 2026 installs some configuration of those five. Skip one and the corresponding failure mode shows up reliably. Skip filesystem and the agent can’t checkpoint. Skip sandbox and the agent eventually destroys something. Skip context management and long sessions become incoherent.
The evidence: harness changes now move benchmarks more than model swaps
It’s easy to argue that all of this is just scaffolding around the model, and the model is what really matters. The 2026 evidence pushes hard the other way.
LangChain ran the natural experiment. They took their open-source deep-agent setup and changed nothing about the model. They redesigned the harness: structured verification loops, directory maps and time-budget warnings injected as context, a loop-detection middleware that catches the agent when it’s about to spin, and what they call a “reasoning sandwich” that concentrates the model’s heaviest thinking at the planning and verification phases. The agent moved from rank 30 to top 5 on Terminal Bench 2.0. Same model. Different harness. 25-position jump.
Anthropic’s 2026 Agentic Coding Trends Report put it even more bluntly: harness setup alone can swing benchmarks by 5 or more percentage points. On a saturated leaderboard where the top systems are clustered within 10 points of each other, that’s the difference between “leading” and “also-ran.”
And the macro number: 88% of agent projects never reach production. That number has not improved as the models have improved. The bottleneck stopped being the model some time in 2025. The bottleneck is the surrounding system.
Distinguishing harness engineering from its neighbors
Three terms get used in adjacent ways. They’re not the same.
Prompt engineering is about what you put in a single instruction to the model. “You are a senior backend engineer. Answer in Markdown. Be concise.” It’s the smallest unit of agent control.
Context engineering is about what’s inside the context window at any moment. System prompt, tool definitions, message history, retrieved documents, MCP results. It treats the window as a finite, curated resource (Anthropic on effective context engineering).
Harness engineering is the outer ring. It’s the whole system around the model: the tools the model has, the sandbox those tools run in, the memory that persists between sessions, the sensors that catch the agent’s mistakes, the guides that prevent the mistakes in the first place. Context engineering is one component of harness engineering, specifically the component that decides what fills the context window.
When you read about “agent observability,” “tool use,” “skills,” “MCP servers,” “evals,” “permissioning,” “compaction,” and “sandboxing,” those aren’t separate disciplines. They’re all components of a harness, viewed through different vendors’ marketing.
A foothold: what you can install today
Even a single article can’t unpack every harness component. But anyone who wants to start working with the discipline today can install a working harness from PyPI in one command.
For a Python repo, the fastest path is Aider: pip install aider-chat. Aider is a terminal pair programmer that understands git repositories, runs your tests, and refuses to commit if they fail. It’s a complete inner harness that fits in a single Python package.
For something closer to a full coding agent system, OpenHands ships an MIT-licensed software-agent SDK that is currently a top performer on SWE-bench. pip install openhands-sdk and you have a Python library that handles the entire inner harness: file editing, code execution, browser automation, sandboxing, the agent loop.
For the orchestration layer (when one agent isn’t enough), LangGraph gives you a graph-based agent runtime with checkpointing, mid-loop state persistence, and the middleware hooks you’d use to insert your own harness logic. pip install langgraph.
For the curated map of every relevant package and paper, the awesome-harness-engineering repo is the closest thing the field has to a canonical list.
We’ll come back to all of these tomorrow when we walk through how Anthropic, OpenAI, LangChain, and Stripe each built theirs in production.
Why this discipline is forming right now, and not earlier
Harness engineering didn’t suddenly appear in 2026. Most of the components are older. Sandboxing, retry logic, observability, evaluation harnesses, structured logs: none of this is new. Software engineering has had these for decades.
What’s new is that we now have a thing they all wrap around: a non-deterministic, capable, expensive, occasionally surprising model that can be asked to take actions in the world. The wrapping changes when the thing being wrapped is a model rather than a deterministic program. Sandboxes have to assume the agent will sometimes try things it shouldn’t. Sensors have to assume the agent will sometimes fool itself. Memory has to assume sessions will end and resume at unpredictable points. Compaction has to assume the window will run out mid-task.
A discipline is the right word for what’s emerging. Not a framework, not a product, not a buzzword. A working body of knowledge about how to build the scaffolding around a model so the model can do real work. It will look obvious in five years and it looks like the central question right now.
What’s coming the rest of this week
Tomorrow we walk through four real harness designs that have been published in 2025 and 2026: Anthropic’s initializer-plus-coding-agent pattern, OpenAI’s Codex harness, LangChain’s deep-agent rebuild that produced the rank-30-to-top-5 jump, and Stripe’s “minions” that have shipped real code in production.
Saturday is the hands-on piece. Thirty-minute setup for a Python repo, with the exact files and the exact packages.
Sunday closes the series with five anti-patterns that quietly sabotage coding agents, and how to spot each one before it costs you a week of debugging.
References and Further Reading
Böckeler, Harness engineering for coding agent users (Martin Fowler’s site, April 2026). The clearest published mental model for the user view of harness engineering. Required reading.
LangChain, The Anatomy of an Agent Harness. The five-primitives decomposition referenced throughout this piece.
LangChain, Improving Deep Agents with Harness Engineering. The rank-30-to-top-5 case study with concrete before/after.
Anthropic, Effective Harnesses for Long-Running Agents. The initializer + coding-agent pattern, with a runnable quickstart.
OpenAI, Harness Engineering. OpenAI’s framing of the discipline behind Codex.
Anthropic, Effective Context Engineering for AI Agents. The context-engineering precursor that harness engineering subsumes.
Anthropic, 2026 Agentic Coding Trends Report. The “5+ percentage points from harness alone” finding.
ai-boost/awesome-harness-engineering. The curated list of every important package and paper in the discipline.
OpenHands software agent SDK. The MIT-licensed Python SDK that is currently a top SWE-bench performer.
Aider. The fastest install for hands-on harness experimentation on a Python repo.