
What Is Fara1.5?
Microsoft’s Open Browser Agent That Beat OpenAI Operator At Its Own Job

Five sentences to take with you
Fara1.5 is an open-weights family of browser computer-use agents from Microsoft Research at 4B, 9B, and 27B parameters, released May 22, 2026.
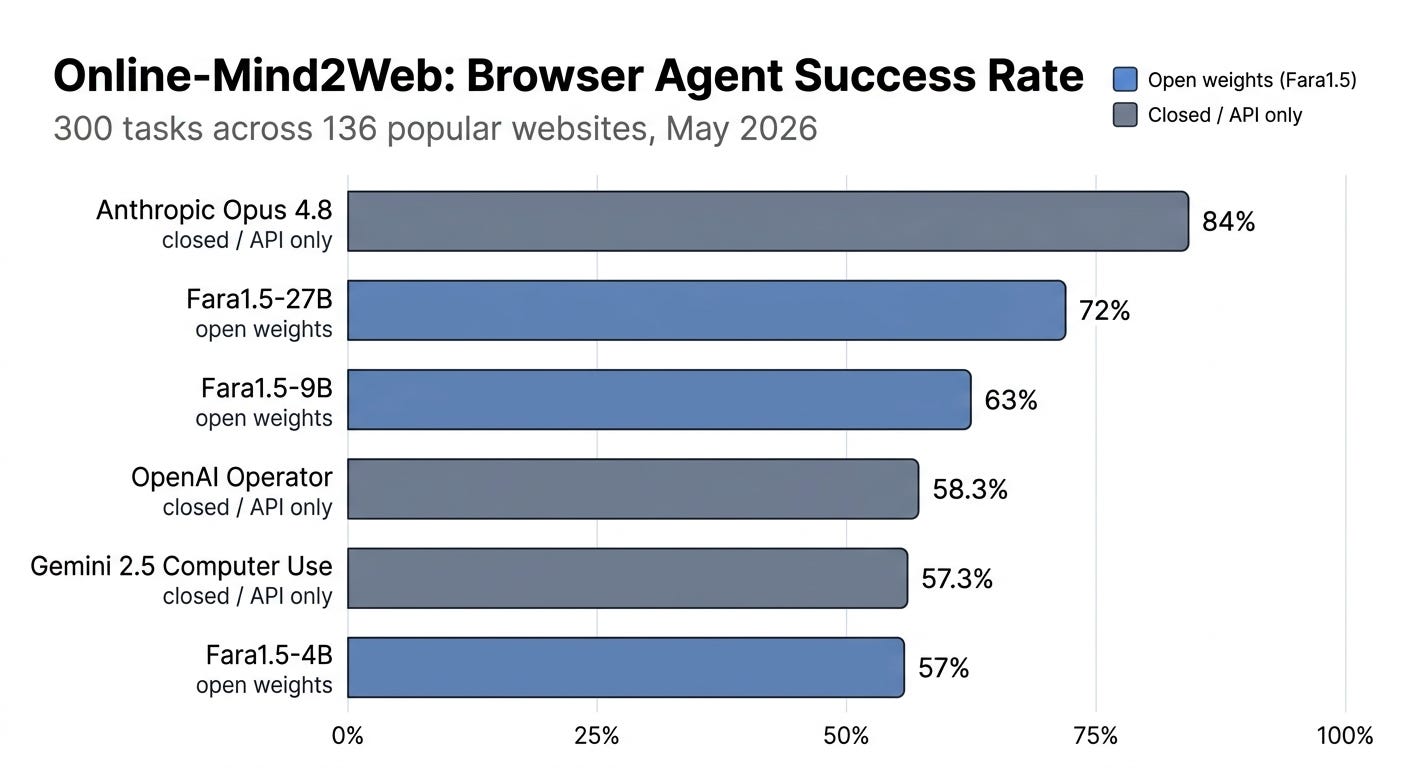
On Online-Mind2Web, the 300-task browser benchmark, the 27B model scores 72%, beating OpenAI Operator at 58.3% and Gemini 2.5 Computer Use at 57.3%.
The 4B model lands at 57%, meaning Microsoft’s smallest open release is already on par with closed flagships from two of the largest labs.
For teams that can’t or won’t ship browser sessions to a vendor, this is the first credible self-hostable option for things like form-filling, booking flows, and price comparison loops.
Yesterday’s piece flagged that most agent benchmarks are exploitable, so a benchmark win is not a victory lap, and Anthropic’s Opus 4.8 still scores 84% on the same eval from a closed API.
A small open model just outscored OpenAI’s flagship browser agent by almost 14 points. Not on a synthetic benchmark someone cooked up for the press release. On Online-Mind2Web, the 300-task evaluation that the field has been quietly converging on for browser agent comparisons.
The model is Fara1.5 from Microsoft Research. Open weights. Three sizes: 4B, 9B, 27B. The 27B version scored 72%. OpenAI Operator scored 58.3%. Gemini 2.5 Computer Use scored 57.3%. Anthropic’s Opus 4.8, which is closed and API-only, scored 84%.
That spread tells you two stories at once. The closed frontier still wins on raw ceiling. But on the open side, the leaderboard just shifted from “nothing usable” to “a 27B model that beats two of the biggest names.”
Why a benchmark win matters less than it usually does
Yesterday’s piece walked through how every major agent benchmark in the last year has had exploits or contamination issues. Online-Mind2Web isn’t immune. Browser benchmarks degrade fast because real websites change, captchas evolve, and the labeling is partly human-judged.
So treat the 72% as a directional signal, not a stable ranking. The thing worth paying attention to isn’t the absolute score. It’s the gap between an open 4B model (57%) and OpenAI’s closed flagship (58.3%). When the smallest model in your release matches your competitor’s biggest product, scale isn’t the moat anymore.
That’s the story.
What Fara1.5 actually is
Fara1.5 is a family of three computer-use agents trained specifically for browser tasks. They’re built on top of Qwen3.5, so the base is open-source already, and Microsoft fine-tuned them for a tight task space: clicking, typing, scrolling, reading, and reasoning over rendered web pages.
The models ship integrated with MagenticLite, Microsoft’s sandboxed browser harness. You can run them through that or wire them into your own browser automation layer. Weights are public.
Compare that to Operator, where you send sessions to OpenAI’s servers and pay per action. Or Gemini 2.5 CU, which lives behind Google’s API. Or Claude’s computer use mode, which runs in Anthropic’s API only. Fara1.5 is the first credible “I can host this myself” entry in the browser agent space.
Simply put: it’s the open-source answer to “can I automate a browser without a vendor watching every click.”
The mental model: narrow training beats broad scale
Here’s the part builders should sit with. Fara1.5-27B beating Operator isn’t a statement about base model quality. Operator is built on a much larger general-purpose foundation. The gap exists because Fara1.5 was trained on a much narrower distribution: browser tasks, with browser-shaped data, evaluated on browser benchmarks.
When the task is narrow and well-defined, task-specific post-training closes most of the gap to a much larger general model. Sometimes it overshoots, like here.
This is the same pattern that played out with code models last year. A 7B model fine-tuned on code can beat a 70B general model at Python completion. It just can’t write an essay. Fara1.5 is that, but for the browser DOM and pointer events.
The implication: for narrow agent verticals, the right strategy probably isn’t “wait for GPT-6.” It’s “fine-tune a mid-size open model on your task.” Microsoft just shipped the proof.
How it works in practice
The models take screenshots and accessibility trees of a browser page, plus the user’s goal, and emit action tokens: click at coordinate, type a string, scroll, navigate, wait. Standard computer-use loop.
What’s different is the training data. Microsoft’s research blog describes the data pipeline as heavy on synthesized browser trajectories at scale, with human-validated rollouts for the hardest task categories. The 9B model nearly doubled its predecessor Fara-7B’s performance (63% vs. ~35% on Online-Mind2Web), which suggests the data work, not the parameter count, is doing most of the lifting.
For deployment, MagenticLite gives you the sandboxed browser, the action loop, and the policy boundaries. You point the model at a goal like “find the cheapest flight from SFO to JFK next Tuesday morning” and it drives the browser until it has an answer or hits a stop condition.
Where this matters in the agentic browser landscape
The open-source browser agent space has been thin. Browser Use is the closest thing to an open standard, but it’s a harness, not a model. You still bring your own brain, and the strongest brains were all closed.
The agentic browser landscape circa May 2026 breaks roughly into three layers: the browser substrate (Playwright, Chrome DevTools Protocol, Browser Use), the model (this was the closed bottleneck), and the orchestration layer (LangGraph, MagenticOne, custom harnesses). Fara1.5 fills the model gap that the rest of the open stack was waiting on.
A team can now stand up a fully self-hosted browser automation pipeline: Browser Use as the harness, Fara1.5-9B or 27B as the brain, your own orchestration on top. No vendor sees the sessions. No per-action billing. No rate limits other than your own GPUs.
That’s the unlock. Not the benchmark number.
What the open-vs-closed gap still buys you
Don’t read this as “closed flagships are over.” Opus 4.8 at 84% on the same benchmark is a 12-point gap over Fara1.5-27B. That’s not a rounding error.
What that 12 points buys, roughly:
Better recovery from unexpected page states (modals, captchas, layout shifts)
Stronger multi-step reasoning when a task chains across 5-10 sites
Better natural-language goal interpretation when the user is vague
For high-stakes flows like booking travel for a CEO, processing insurance claims, or running QA on a production site, that gap matters. For lower-stakes batch work like price scraping, form filling at scale, or QA on staging environments, Fara1.5-9B is probably the new default.
The decision tree is the same one teams ran for code models in 2024 and 2025. Frontier closed for the hard end. Mid-size open for the long tail.
Why “self-hostable browser agent” is a real category now
Browser sessions are unusually sensitive. They carry cookies, auth tokens, customer data, internal admin panels, sometimes payment flows. Most enterprise security teams will block any tool that sends a browser session to a third-party API.
That’s why Microsoft Copilot Studio’s computer-use docs emphasize the sandboxed VM model. It’s not a UX choice, it’s a procurement one. Customers were asking.
With Fara1.5, the procurement question gets easier. The whole inference loop can live inside the customer’s tenancy. No data exfiltration risk. No audit log of every click going to a vendor. For regulated industries (healthcare, finance, government) that’s the difference between “browser automation pilot blocked by security review” and “browser automation in production.”
The common misconception
A lot of the discussion around Fara1.5 has framed it as “Microsoft caught up to OpenAI.” That misreads what happened.
Microsoft didn’t catch up. They ran a different play. Operator and Gemini 2.5 CU are general-purpose agent products bolted onto frontier foundation models. Fara1.5 is a specialized open release optimized for one task class. They’re not competing for the same shelf.
The correct frame is closer to Whisper. When Whisper dropped, it didn’t replace the closed speech APIs everywhere. It replaced them in the specific cases where teams needed self-hosting, language coverage, or cost control. The closed APIs kept the high-end voice product market. Fara1.5 is the Whisper moment for browser agents.
When to use it, when not to
Use Fara1.5 (likely 9B or 27B) if:
You need browser automation inside a tenancy boundary you control
Your task distribution is well-defined: forms, comparisons, structured navigation
Per-action vendor pricing is the binding constraint
You have GPU capacity to host a 9B-27B model at acceptable latency
Stay on Operator, Gemini 2.5 CU, Opus 4.8, or whatever’s closed and current if:
Your tasks routinely chain across many heterogeneous sites
The browser flow needs strong recovery from edge cases
You don’t have ML ops capacity to keep an open model running well
Latency-to-first-click matters more than per-action cost
The boring middle case (mid-complexity, mid-stakes, moderate volume) is where the new open model will probably eat the most share. That’s where vendor pricing math gets ugly fastest and where 9B is usually good enough.
How to evaluate it before you commit
Don’t trust the benchmark. Run your own.
Pick 20-50 tasks that represent your actual use case. Not Mind2Web’s tasks. Yours. Score them on success rate and time-to-completion. Compare Fara1.5-9B against whatever you’re currently paying for. Then make the call.
This is the only way to handle the benchmark-trust problem from yesterday’s piece. Public benchmarks degrade. Internal eval sets, scoped to the work you actually do, hold up because you’re the only one who can game them.
Anthropic’s own release notes for May 2026 make the same point implicitly: published scores are marketing, internal scores are decisions.
References and Further Reading
MarkTechPost coverage of the Fara1.5 release: the cleanest summary of the release including benchmark numbers and model sizes
Microsoft Research blog on MagenticLite, MagenticBrain, Fara1.5: the primary source from Microsoft Research, including training data discussion
Fara1.5 model card and research article: technical detail on the model family
Browser Use review, the open-source browser harness landscape: context on what the open browser agent stack looked like before Fara1.5
Agentic browser landscape 2026: map of the closed and open players in browser agents as of May 2026
Microsoft Copilot Studio computer-use docs: the enterprise deployment context for sandboxed browser agents
Anthropic May 2026 release notes: Opus 4.8 computer-use context and the closed-side comparison
Online-Mind2Web benchmark context: what the benchmark measures and how to read agent leaderboards generally