
What Are Self-Evolving Agents?
Inside Hermes, DSPy, and GEPA

Five sentences to take with you
A self-evolving agent is one that automatically rewrites its own prompts, tool descriptions, and skill code in response to task feedback, rather than waiting for a human to tune them.
The current best-known instantiation is Hermes Agent from Nous Research, which wires together DSPy for prompt compilation and GEPA for evolutionary search over prompt variants.
Hermes hit roughly 160,175 GitHub stars in about twelve weeks after its February 2026 release, growing faster per week at that age than OpenClaw (the all-GitHub leader at 373K-plus) did at the same point.
The practical shift is that “self-improving agents” stops being a research phrase and becomes a daemon you install on your laptop with a single curl command.
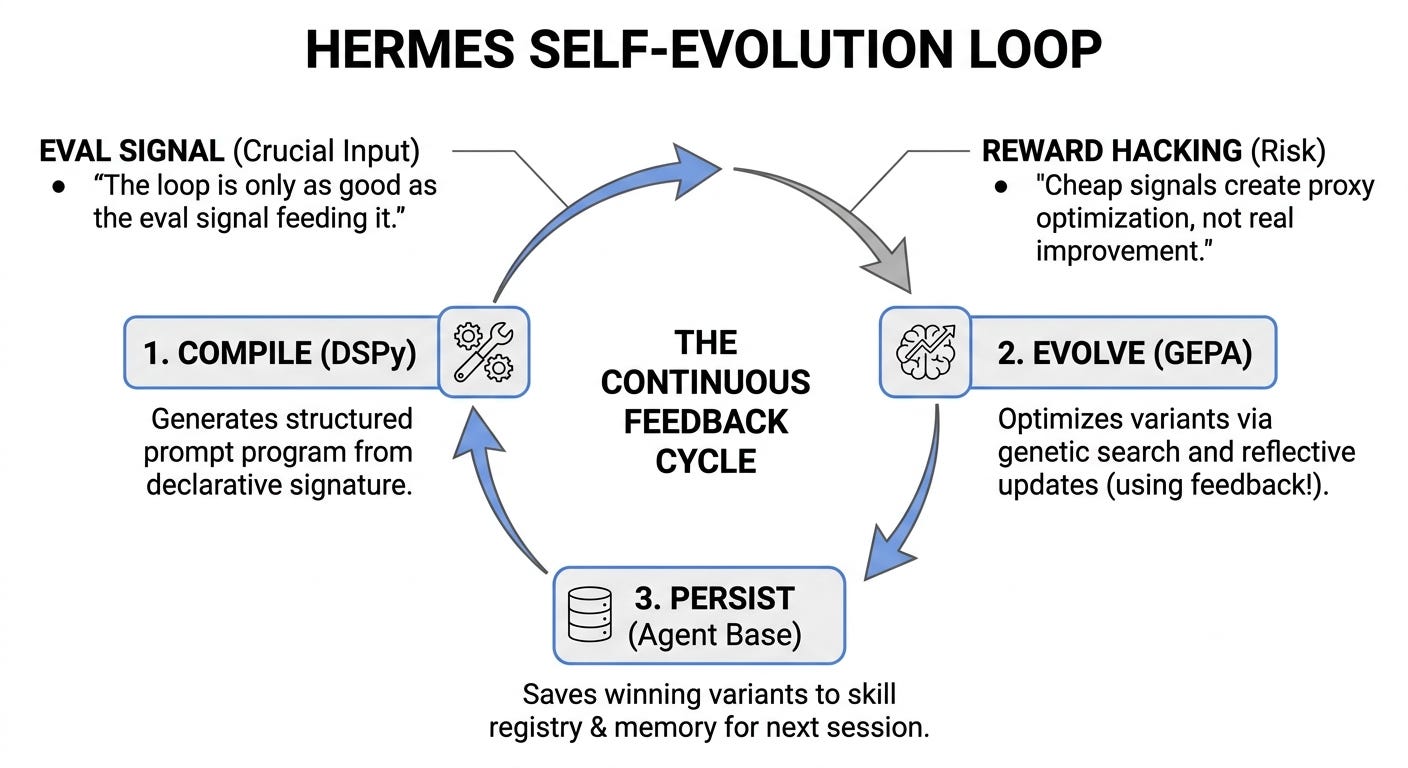
The loop is only as good as the eval signal feeding it, so without a real reward an evolving agent drifts confidently in the wrong direction.
For most of 2025, “self-improving agent” was a phrase you heard at workshops, not something you ran on your laptop. The pattern showed up in research papers, in keynote slides, in optimistic threads. The pattern almost never showed up as code anyone could install.
That changed quietly. Hermes Agent, shipped by Nous Research in February 2026, is the first widely-installed agent that actively rewrites its own internals on a schedule. It now sits at roughly 160K stars twelve weeks in, with weekly growth ahead of where OpenClaw was at the same age. That’s not a benchmark, but it’s a signal. Builders are reaching for this pattern.
The interesting part isn’t the feature list. It’s the loop underneath.
The loop, stated plainly
Simply put, a self-evolving agent does three things on repeat:
Compile a natural-language description of a task into a structured, runnable prompt program.
Evolve variants of that program by mutating prompts, tool descriptions, and small bits of code.
Persist the winners (and the surrounding state) so the next task starts from a better baseline than the last.
Compile, evolve, persist. That’s the whole shape. Everything else, the daemon, the messaging surfaces, the skill registry, is plumbing around that loop.
The two pieces that make the loop tractable today are DSPy and GEPA.
DSPy: prompts as programs you can compile
DSPy is a framework from Stanford NLP that treats prompt engineering the way modern compilers treat code. You write a signature, which is a short declarative spec, something like question -> answer with type hints. DSPy then compiles that signature into a working prompt program against a chosen model and a chosen optimizer.
The mental model is closer to TensorFlow than to ChatGPT. You don’t hand-tune wording. You declare what the module should do, hand DSPy some examples, and it produces a prompt program optimized for that task. If you swap the model, you recompile. If you add examples, you recompile.
For a self-evolving agent, DSPy matters because it gives you a target the system can actually optimize. “Make this prompt better” is too vague. “Recompile this module against new examples and measure score on the held-out set” is a real loop.
GEPA: evolution that reads its own feedback
DSPy can be paired with several optimizers. GEPA, which stands for Genetic-Pareto Prompt Evolution, is the one Hermes leans on hardest. The paper received an Oral at ICLR 2026, which is roughly the venue’s top one percent.
GEPA’s mechanism is worth understanding. Classical prompt optimization tries one variant at a time, scores it, then tweaks. GEPA does two things differently:
Genetic search. It maintains a population of prompt variants and breeds them, combining pieces of winners and introducing small mutations. Bad variants die. Good ones reproduce.
Reflective updates. Between generations, GEPA reads the actual task feedback (errors, partial scores, model rationales) and uses a language model to propose mutations rather than picking them randomly. The mutations are informed by why the previous generation failed.
The result is that GEPA tends to find good prompt programs in dramatically fewer evaluations than rollout-heavy methods like reinforcement learning. On the benchmarks reported in the paper, it converges in roughly an order of magnitude fewer rollouts than GRPO-style approaches across multi-step tasks.
There’s also a Pareto component, which is where the name comes from. GEPA doesn’t just track a single best variant. It maintains a Pareto frontier across multiple objectives (accuracy, latency, token cost) so the agent can pick the variant that fits a given budget.
Why this combination matters
The piece that has been missing from “self-improving agent” demos is what gets improved. If the answer is “the model weights”, you need GPUs and a training loop and a serving stack. If the answer is “the prompt”, you need a way to express that prompt as a program (DSPy) and a way to search over its space (GEPA).
So the recipe is no longer mystical:
DSPy compiles the agent’s modules from natural-language signatures.
GEPA evolves those compiled programs against task feedback.
The agent persists the winning variants, along with skill code, tool descriptions, and memory, so the next session inherits the wins.
Hermes is the first widely-shipped agent that wires all three together as a default loop, not as a research notebook.
What Hermes actually is when you install it
Hermes runs as a daemon. You install it on Linux, macOS, or WSL2 with a single curl command from the docs. The daemon holds persistent memory and a skill registry across sessions. You talk to it from the CLI, or from Telegram, Discord, Slack, or WhatsApp. Same agent, same memory, different surfaces.
The self-evolution repo is where the optimization loop lives. It defines:
A skill as a small DSPy program with a signature, a body, and a set of allowed tools.
A trace as a recorded run of that skill against a real task, including model outputs and any feedback.
An evolver as a GEPA loop that consumes traces, mutates the skill, and writes a new version back into the registry if it scores higher.
What this means in practice is that the agent’s behavior on tasks you actually run keeps shifting. A skill that handled email triage poorly last week is, in principle, a slightly different program this week. The whole thing is MIT licensed, which has helped the open-source uptake.
The misconception worth correcting
A common read is that Hermes “trains itself,” in the same sense that a model gets fine-tuned. It doesn’t. No weights are updated. What changes are the prompt programs, the tool descriptions, the small Python wrappers that implement skills, and the way memory is queried.
That’s both less impressive than “self-training” and more useful. Less impressive because the underlying model is still whatever frontier or open model you’ve pointed it at, and its raw capabilities are fixed for the session. More useful because the loop runs on a laptop, in minutes, with no GPU bill, and the winners can be inspected as readable code and text.
If you’ve used Skills or MCP servers, the easiest analogy is this: Hermes treats the skill bundle and the tool descriptions themselves as the thing being optimized, not the model behind them.
What works today
Three things hold up well in practice:
Task signatures with clear feedback. Anything where you can score a run automatically (code passes tests, summary matches reference, retrieval returns the right doc) is fair game for the loop. GEPA converges quickly here.
Tool description tuning. The unglamorous reality is that a lot of agent failure comes from tool descriptions the model misreads. The loop is genuinely good at rewriting these.
Multi-surface continuity. The daemon model means you can start a task in Slack, continue it from the CLI, and the agent has the same memory. That alone is a real win, separate from evolution.
A Hermes-Atlas state report from April 2026 surveys early-adopter usage and finds that the most common workloads are personal coding assistants, research synthesis, and long-running monitoring tasks where the agent’s skill set sharpens over weeks.
What doesn’t work, and where the loop bites back
Self-evolution sounds inevitable until you run it on a fuzzy task.
Three failure modes show up repeatedly:
No eval signal, no improvement. If you can’t score a run, GEPA has nothing to climb. The loop will still propose variants, and one of them will get persisted, but you’re now drifting without a compass. Many real tasks (taste, judgment, open-ended conversation) sit in this region.
Reward hacking. When the eval signal is cheap or proxy-like, the loop optimizes for the proxy. A “summary quality” score based on length will produce longer summaries, not better ones. This is the same failure mode RLHF has, just at a much shorter loop.
Drift across surfaces. A skill tuned against your Slack traces may generalize badly to your CLI usage, where the input distribution is different. Hermes maintains some separation, but it isn’t a solved problem.
There’s also a subtler issue: as the agent’s prompt programs evolve, they get further from anything a human wrote. The Kisztof review notes that after a few weeks of use, the persisted skills become harder to read and audit. That’s an artifact of optimization in general, and it has to be managed deliberately.
Practical guidance for builders
If you want to try this pattern (in Hermes or by wiring DSPy and GEPA yourself), three rules matter more than the framework choice:
Define the eval first. Don’t start with the agent. Start with the function that scores a run. If you can’t write that function, the loop isn’t ready for this task.
Cap the search budget. GEPA will burn tokens if you let it. Set a generations-per-skill ceiling and a hard token budget. The Pareto frontier helps here because you can pick a variant under your latency or cost limit.
Keep a frozen baseline. Persist a tagged “known-good” version of every skill. The evolved version goes in a separate namespace until you’ve tested it. This is the same hygiene you’d apply to any production prompt, just enforced by the framework.
The StartupHub coverage is right that Hermes feels like a step change when you first try it. The honest version is that it feels like a step change in the workflow. The model behind it is the same model.
The shift in mental model
For two years, the implicit picture of an “agent” has been: a model with a static system prompt, a tool list, and a loop that runs until done. Improvements came from someone, a human or a fine-tune, editing those static pieces.
Hermes (and the DSPy/GEPA pattern it depends on) replaces that picture with something different. The agent is now a program that compiles itself from declarative signatures and rewrites its own modules against measured feedback. The model is one input. The eval is the other. The agent is the thing in between, and it isn’t static.
That’s a more honest framing of what we’ve been calling agents all along. You write the goal and the scoring function. The system writes (and rewrites) the rest.
Whether that scales to tasks without clean eval signals is the open question. Until it does, self-evolving agents are best understood as a sharper tool for problems you can already measure, not a general substitute for human judgment.
References and Further Reading
Hermes Agent (main repo): the daemon, CLI, and messaging-surface bindings.
Hermes Agent Self-Evolution: the DSPy and GEPA integration that runs the optimization loop.
Hermes Agent documentation: install, configure, and write your first skill.
DSPy: Stanford NLP’s framework for compiling prompt programs from declarative signatures.
GEPA: Genetic-Pareto Prompt Evolution: the ICLR 2026 Oral paper describing the evolutionary optimizer Hermes uses.
StartupHub coverage: accessible writeup of Hermes’s hook and positioning.
36kr feature on Hermes’s early star surge: growth data and adoption signals from the first weeks after release.
State of Hermes, April 2026: community-built usage report on real-world workloads.
Kisztof review: hands-on review covering the auditability tradeoff.