
Five Harness Anti-Patterns That Quietly Sabotage Coding Agents

Five sentences to take with you
Most “the agent is dumb” complaints are harness failures in disguise; the model is doing its job and the scaffolding is letting things slip through.
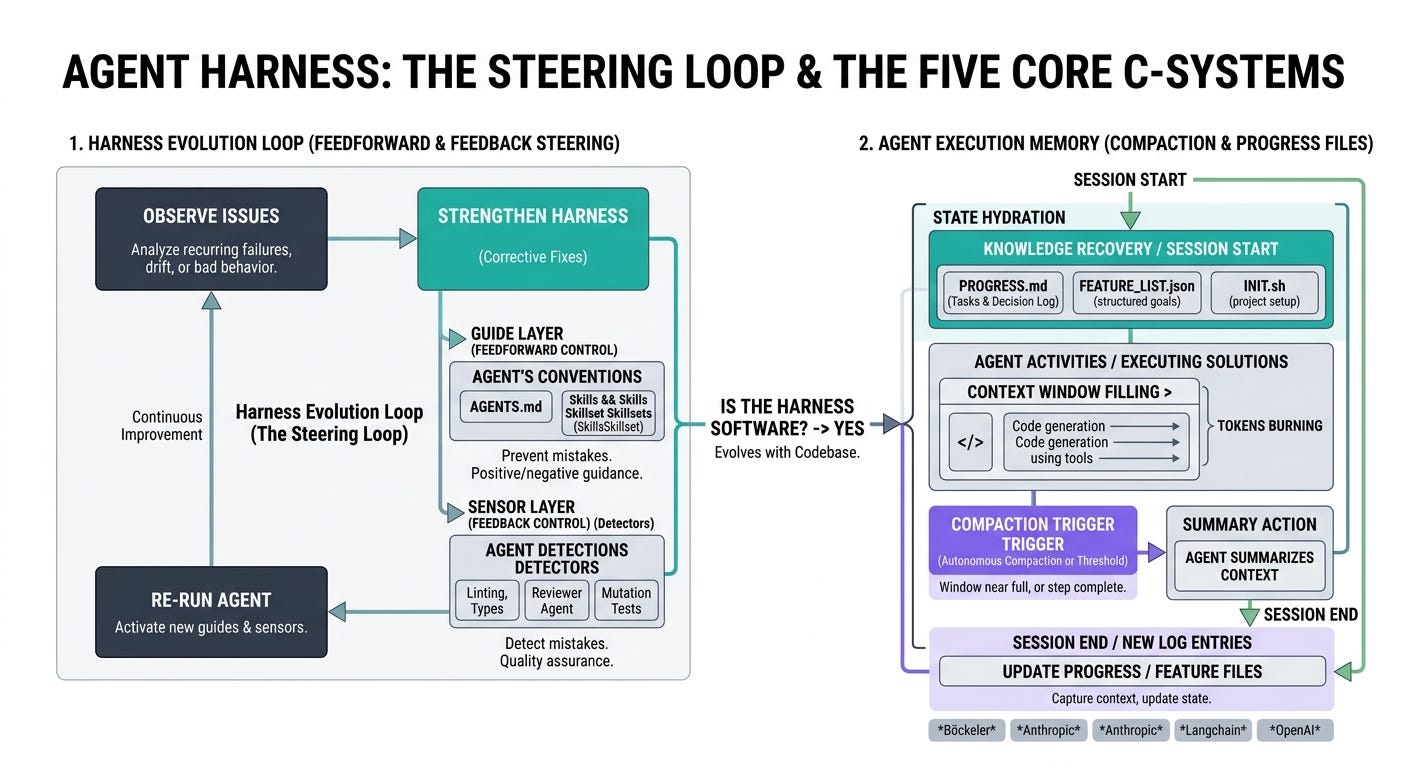
Five anti-patterns recur across teams: no guide layer, no sandbox, sensors that never fire, no compaction or progress files, and treating the harness as a one-time setup.
Each has a recognizable symptom, a different root cause, and a fix that takes less time than debugging the symptom one more round.
The hardest is “sensors that never fire” because green builds feel like success until you realize the sensors don’t exercise the new behaviour.
Harness engineering rewards a steering loop: every recurring failure becomes a new guide or sensor, so the harness strengthens as the codebase changes.
Every agent harness that ships eventually hits all five of these.
If you followed yesterday’s recipe, you now have a working harness on a Python repo. It will not stay working without active maintenance, and the failure modes are the same ones every team eventually meets. Naming them in advance is the cheap version. Spotting them in your own setup is the expensive version. We’ll do the cheap version today.
Anti-pattern 1: no AGENTS.md, no skills, no guide layer
Symptom. The agent’s output style drifts session to session. Conventions you established in week one quietly reappear in week six. Things you “fixed” silently drift back. New code uses a different import style than the rest of the codebase. The agent doesn’t know that you switched to polars two months ago, so it keeps proposing pandas.
Root cause. The agent has no project-level instruction file. Every session, it infers conventions from the code it can see. The conventions it infers are biased toward whatever it was trained on, which is rarely identical to whatever your repo does. The longer the project runs, the more drift accumulates.
The fix. Write an AGENTS.md and keep it current. The single most undervalued section is the negative one: “Things that have bitten us before.” Positive guidance (do X) is useful; negative guidance (don’t do Y, because Y looked reasonable last quarter and burned us for a week) is the kind of context the agent literally cannot derive from the code alone. It comes from human memory and has to be written down.
A harness without a guide layer is a contractor with no spec. You can hire the best contractor on earth and you will still get something you didn’t ask for, because the spec is in your head.
Anti-pattern 2: no sandbox, or “sandboxed” by trust
Symptom. One day the agent runs git push --force origin main. Another day it deletes a file outside the repo. Another day a model decides the right way to fix a memory leak is to chmod 777 the data directory. Eventually one of these happens to a customer.
Root cause. The agent has direct access to your shell, your filesystem, and your git remotes. The “sandbox” is whatever the agent decides to limit itself to. That is not a sandbox.
The fix. Run the agent inside a real isolation boundary. The cheapest version is a Docker container: the agent runs as a non-root user, with the repo bind-mounted in, with no network access except what you allow, and with no write access to your global git config or SSH keys. Anthropic’s quickstart and OpenHands both default to this kind of containerized environment.
For tools that touch external services (git remotes, package registries, your cloud account), use a permission system that asks for approval before destructive operations. Anthropic’s Beyond Permission Prompts is the canonical writeup of how to build this properly. The short version: don’t put “please confirm before doing dangerous things” in the system prompt and hope. Build it into the tool layer where the model can’t ignore it.
A harness without a real sandbox is one bad weekend away from a postmortem.
Anti-pattern 3: sensors that never fire
Symptom. Ruff passes. MyPy passes. The whole test suite is green. The CI badge is green. The agent reports success. The code is wrong. A user files a bug. You look at the diff, and the code does exactly what the linter said it should and exactly what the test said it should, and exactly nothing useful.
Root cause. Your sensors are running, but they aren’t testing what you thought they were testing. The lint passes because there’s no Ruff rule for the actual problem. The tests pass because the agent helpfully wrote a test that asserts the buggy behaviour is correct. The CI passes because nobody’s looking at coverage.
The fix. This is the hardest one. Three things in combination:
Mutation testing. Tools like
mutmutorcosmic-rayintroduce small bugs into your code and check whether your tests catch them. If most mutations survive, your tests aren’t actually testing the behaviour. Mutation testing is the canonical way to validate that your sensors fire when they should.A code-review sensor that reads the diff against the spec. Yesterday’s
scripts/review.pyis a starting point. The reviewer agent should look specifically for “the agent wrote a test that’s locked to its own (possibly wrong) implementation.” This is a known LLM failure mode that human reviewers also miss.A periodic janitor sweep. OpenAI’s Codex harness runs “garbage collection” passes that proactively look for dead code, redundant tests, over-engineered solutions. Run something similar against your own codebase monthly.
Sensors that never fire feel like quality. They are a more dangerous failure than sensors that fail loudly, because nothing in the system tells you the silence is wrong. As Birgitta Böckeler put it: “If sensors never fire, is that a sign of high quality or inadequate detection mechanisms?” You have to check.
Anti-pattern 4: no compaction, no progress files, long-session amnesia
Symptom. The agent works for a few hours, hits the context window, then starts behaving strangely. It “fixes” things that were already fixed. It re-implements a function it wrote three sessions ago, but worse. It declares the project complete with half the features missing. It burns thousands of tokens on every session catching up to where the last session left off.
Root cause. Context windows are finite and sessions outlive them. Without a written record of what’s been done and what’s pending, every new session starts cold. The model fills the gap by guessing, and the guess is usually wrong in subtly different ways each time.
The fix. Adopt the Anthropic long-running-agents pattern even if your sessions aren’t that long:
A
progress.md(orclaude-progress.txt) that records what was decided and what’s pending. The agent reads it at session start and updates it at session end.A structured feature file (
feature_list.jsonorPlan.md) for any task that won’t finish in one session. Anthropic’s claude.ai-clone example produced over 200 features. Each one has apasses: falseflag the agent flips only after end-to-end verification.An
init.shso the agent doesn’t waste tokens figuring out how to run the project from scratch every session.Compaction strategy: when the window starts filling, summarize older context into a brief and continue. LangChain’s autonomous compaction lets the agent decide when to compress; the older approach is to compress at a hard token threshold.
Anthropic’s Claude Agent SDK quickstart is the cleanest reference implementation. Lift the structure and rename the files to match your project.
A harness without memory is a harness that re-derives reality from scratch every session. That’s exactly as efficient as it sounds.
Anti-pattern 5: treating the harness as a one-time setup
Symptom. Six months after yesterday’s tutorial, AGENTS.md says the project uses pandas but it migrated to polars last quarter. The pre-commit hooks haven’t been updated. The code-review skill is looking for issues that haven’t been issues since spring. The agent’s behaviour drifts. You blame the model. You upgrade the model. The drift continues.
Root cause. The harness is software. Software has technical debt. A harness that doesn’t evolve is technical debt accumulating in your most important quality-control system.
The fix. The steering loop, in Birgitta Böckeler’s terms. Every time an issue happens multiple times, the harness gets a new control to prevent the recurrence. A new guide if it’s a feedforward problem (the agent didn’t know X). A new sensor if it’s a feedback problem (the agent did X and nothing caught it). The harness gets stronger every week, not just on the day it was set up.
A few mechanical practices that help:
Treat
AGENTS.mdas a file that gets edited on every architectural decision. The PR that changes the architecture should also change the docs the agent reads.Audit the pre-commit hooks quarterly. Are the linters catching real issues? Are tests testing real behaviour? Run mutation testing.
Audit the code-review skill quarterly. Have you added types of mistakes the reviewer doesn’t catch?
Audit the sandbox quarterly. Does the agent now have access to things it didn’t have last quarter?
The harness is part of the codebase. Maintaining it is part of maintaining the codebase. Skip the maintenance and the harness silently rots.
The five together
Five anti-patterns, five corresponding fixes:
No guide layer → symptom: drift, inconsistency, lost conventions. Fix: an
AGENTS.mdwith positive AND negative guidance.No sandbox → symptom: an eventual catastrophic action. Fix: a container plus a permission system on destructive tools.
Sensors never fire → symptom: green builds on wrong code. Fix: mutation testing, an inferential reviewer, and monthly janitor sweeps.
Long-session amnesia → symptom: “forgets” what was done, redoes work, declares features done too early. Fix: a
progress.md, a feature file, aninit.sh, and a compaction strategy.One-time setup → symptom: the harness rots as the codebase evolves. Fix: the steering loop; treat the harness as part of the codebase.
A harness that has all five of these problems doesn’t fail loudly. It fails quietly, in a way that looks like the model is getting worse, until someone names the actual cause.
This closes a four-part series on harness engineering. Last Thursday defined the discipline. Saturday walked through how Anthropic, OpenAI, LangChain, and Stripe built theirs. Yesterday gave you a thirty-minute recipe for your own Python repo. Today you have the failure modes to watch for as that harness lives in production.
The rest of the week we’re back to agent news. The Ch3 fundamentals series and this harness series are now a solid foundation. Every later piece in this newsletter can assume both.
References and Further Reading
Böckeler, Harness engineering for coding agent users. The steering-loop framing and the “sensors never fire” question both come from this piece.
Anthropic, Effective Harnesses for Long-Running Agents. The reference design for the
progress.mdandfeature_list.jsonpatterns.Anthropic, Beyond Permission Prompts. How to build a real permission system instead of relying on natural-language permission text.
LangChain, Autonomous Context Compression. The agent-controlled approach to context compaction.
OpenAI, Harness Engineering. The “garbage collection” pattern referenced under anti-pattern 3.
mutmut. Mutation testing for Python. The fastest way to find out whether your tests actually test anything.cosmic-ray. The other Python mutation tester worth knowing.bandit. Security-focused static analysis; the third deterministic sensor in yesterday’s setup.ai-boost/awesome-harness-engineering. The curated list of every important harness package and paper.