
Building an Agent Eval Pipeline That Actually Catches Failures

Five sentences to take with you
An agent eval pipeline turns “it seemed to work” into a number you can defend: collect cases, define good, score every run, gate releases on the result.
The common mistake is grading the final answer only, when the failures that hurt you live in the steps, the tool calls, and the variance across runs.
A pipeline that catches real failures scores the trajectory, runs each case many times to expose variance, and uses perturbed inputs on purpose.
Teams that ship reliable agents treat evaluation as the central activity, putting it at 60 to 80 percent of development time.
The payoff is a regression gate that tells you, before you ship, whether this version is better or worse than the last.
You can’t fix what you can’t see, and right now most teams can’t see their agent fail until a user reports it.
That’s the gap this pipeline closes. Not a benchmark you run once to brag about a number, but a standing system that catches a regression before it reaches production, the same way unit tests catch a broken function before it ships. The teams quietly winning at agents have figured out that evaluation is the central engineering activity, often 60 to 80 percent of their development time. Here’s how to build that loop, piece by piece.
Stop grading the essay, start grading the work
The first instinct is to check the final answer. The agent was asked to do a thing. Did the thing get done? Pass or fail.
That instinct hides exactly the failures you care about. An agent can reach a correct-looking final answer through a broken path: it called the wrong tool, got lucky, retried three times, and burned a fortune in tokens doing it. Grade only the output and that run looks identical to a clean one. Next week the luck runs out and you have no idea why, because your eval never looked at the path.
So the foundational decision is to evaluate the trajectory, the full sequence of decisions and tool calls, not just the endpoint. This is why the modern eval stack is built on tracing: you need a structured record of what the agent actually did before you can judge whether it did it well. We’ll go deep on tracing tomorrow; today, assume each run produces a trace you can inspect.
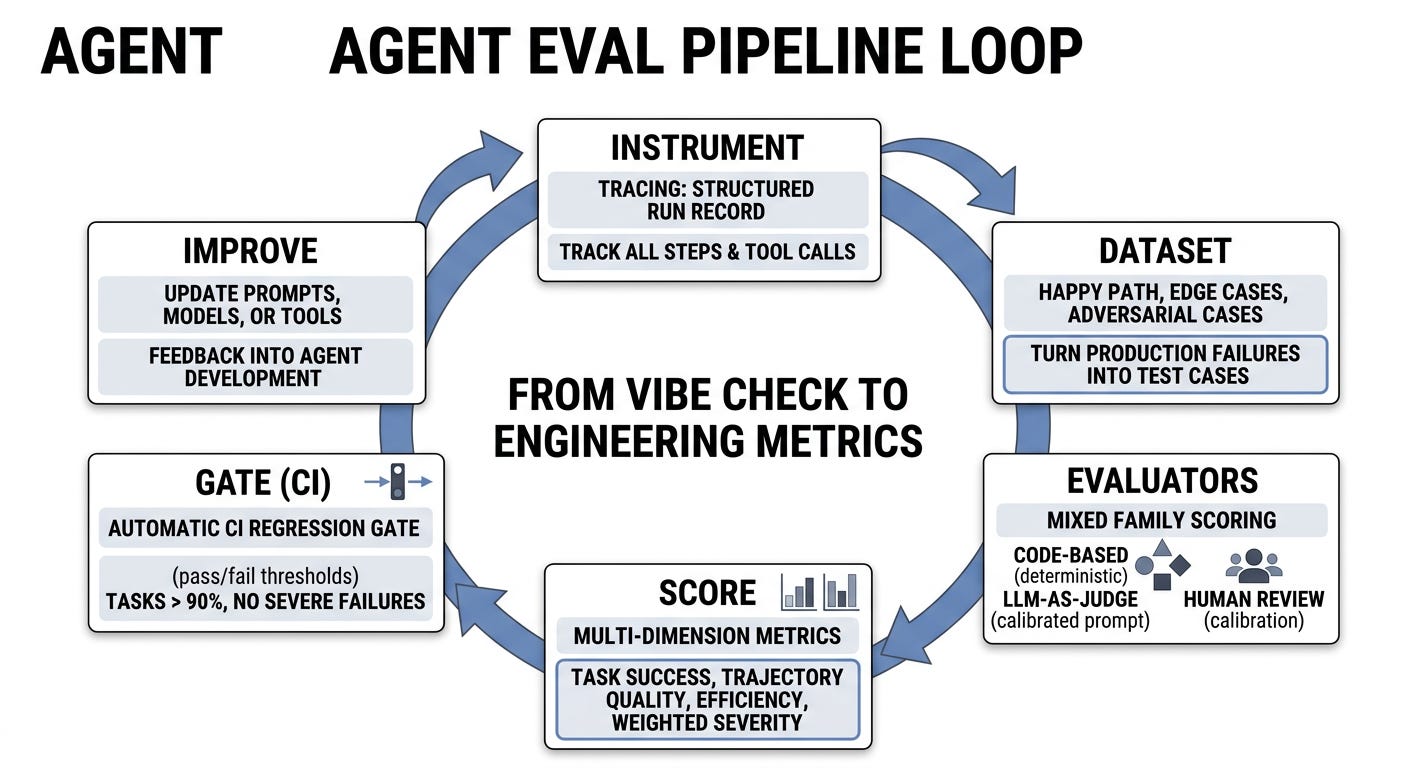
The loop, end to end
A working pipeline has six stages, and they form a cycle: instrument, dataset, evaluator, score, gate, and improve. Each one feeds the next, and the whole thing runs on every meaningful change.
Think of it like a test suite that happens to be probabilistic. Unit tests have inputs, expected behavior, a runner, a pass threshold, and a CI gate. An eval pipeline has the same skeleton, adapted for a system that doesn’t give the same answer twice. The adaptation is the interesting part, and it’s where most homegrown attempts fall short.
Build the dataset from your real failures, not your imagination
The dataset is the heart of the pipeline, and it’s where teams under-invest the most.
Don’t sit in a room inventing test cases. Mine them. Pull real production transcripts, especially the ones that went wrong, and turn each into a case: the input, the relevant context, and a definition of what a good outcome looks like. Every time the agent fails in production, that failure becomes a permanent case in the set, so the same bug can never silently come back. This is regression testing, and it’s the single highest-value habit in the whole pipeline.
Cover three kinds of cases deliberately. The happy path, so you notice if you break the basics. The known edge cases, the weird inputs and rare branches that have bitten you before. And adversarial or perturbed cases on purpose: the same request reworded five ways, a tool that returns an error, a truncated context. If your dataset only contains clean inputs, your eval only proves the agent works when nothing goes wrong, which is the one condition production never offers.
Run it more than once
Here’s the rule that separates an agent eval from a regular test: run every case many times.
A single run tells you almost nothing about a stochastic system. The same input can succeed, fail, and succeed again. So execute each case five, ten, twenty times and look at the distribution. Report the success rate, not a binary pass. Track the variance, because a case that passes 19 of 20 times is a different risk from one that passes 11 of 20, even though both “pass” on a good day. This directly measures the consistency dimension that reliability research identifies as core, and it’s invisible to any pipeline that runs each case once.
When you report results, lead with the worst case alongside the average. Production lives in the tail, and the tail is what a single-run eval throws away.
Choosing evaluators: the three honest options
An evaluator decides whether a given run was good. You have three families, and mature pipelines mix them.
Code-based checks are the gold standard when they apply: deterministic assertions like “the API was called with these arguments,” “the output is valid JSON,” “no action was taken twice,” “the result matches the known answer.” Cheap, fast, and not debatable. Use them everywhere you can.
LLM-as-judge handles the things code can’t easily score: was the response helpful, did it follow the instruction, was the tone right. It’s powerful and it’s fallible, so pin it down. Give the judge a specific rubric, ask for a structured verdict with a reason, and validate the judge itself against human labels before you trust it. A vague judge prompt produces vague, drifting scores.
Human review stays in the loop for the cases that matter most. The strongest setups combine automated metrics with expert human judgment, using humans to spot-check and to calibrate the automated judges, not to grade everything by hand.
Score what failure actually costs
A single pass/fail number flattens the one thing you most need to know: how bad was the miss.
Score along the dimensions that map to real risk. Task success, the headline rate. Trajectory quality, did it take a sane path. Efficiency, how many steps and tokens it burned. And failure severity, the difference between a wrong answer the user catches and an irreversible action taken silently. Weighting by severity is what stops your pipeline from treating a typo and a wrongful refund as the same defect. An agent that fails safely and visibly should score better than one that fails confidently and quietly, and your scoring should encode that.
Make it a gate, not a report
A pipeline you run manually when you remember to is a nice-to-have. A pipeline wired into your release process is a safety system.
The final move is the CI gate. Every change that touches the agent, a new prompt, a new model, a new tool, triggers the eval suite automatically, and the change ships only if the scores clear your thresholds and don’t regress against the previous version. The flow practitioners converge on is clean: instrument, trace, dataset, evaluator, score, then gate. Set explicit bars. Task success above your line. No regression on any existing case. No increase in high-severity failures. If a change can’t clear the bar, it doesn’t ship, and the failing case tells you exactly what broke.
Start smaller than feels satisfying. Twenty real cases, run ten times each, with a handful of code checks and one well-calibrated judge, wired into CI, will catch more real regressions than a hundred hand-invented cases you run by hand twice a quarter.
Why this is the work now
The reason to build this isn’t process for its own sake. It’s that evaluation is the only thing that converts the reliability problem from a feeling into a number you can move.
Every other piece of this week, the compounding math, the runtime fixes, the observability, only pays off if you can measure whether a change made the agent more trustworthy or less. The eval pipeline is that measurement. Build it once, feed it your real failures forever, and you stop shipping on hope. That’s the difference between an agent you demo and an agent you depend on.
References and Further Reading
Building an AI Agent Evaluation Pipeline (Digital Applied): the instrument-to-gate methodology and the role of human judgment.
Best AI Agent Reliability Solutions in 2026 (Future AGI): a survey of tooling for evaluating and monitoring agents.
Towards a Science of AI Agent Reliability (arXiv 2602.16666): the consistency and robustness dimensions your evaluators should measure.
Beyond pass@1 (arXiv 2603.29231): why running each case many times and reporting distributions beats single-attempt scoring.
Grading trajectories instead of final answers is one of those things you only appreciate after an agent fails in a way that looked correct. I have seen the same pattern. Something I have been thinking about alongside this: a paper last week found that in one 5-agent setup, the system entropy roughly doubled every 150 rounds even under fixed conditions. That suggests even a good trajectory eval dataset might need periodic refresh, because the system's stability profile is shifting as it runs.